

A couple of years ago I found a black and white photo from the late 1800s and wanted to figure out what station it was from. Google was useless and only showed unrelated stations, but surprisingly, Bing found a page with the exact photo on it. It was on one of those shitty scraper pages that just lists thousands and thousands of random photos, but nonetheless I figured out what station it was
Jesus Christ I guess I’m not misremembering.
Bing’s reverse image search is essentially dead in 2024 unless you’re uploading the Mona Lisa. It’s really, really terrible and even worse than Google.
My favorites right now are Tineye, Yandex, and Google, in that order.
Strange, for me Tineye has not a single time been able to identify ANY of the images I ever tried. Yandex has worked best for me
Same, tineye only ever worked for me if I uploaded a picture that was by Reuters or something and therefore on lots of reputable sites. In any other cases it found nothing.
It does seem like the ideology of those inside google went from “tech” , to “I know better than you do”. Not sure it’s fixable really…
That’s the problem with most tech these days. They assume they know the best way to do something or know better than you. Its infuriating
It’s about minimizing the annoyance for the majority of users who will misspell some popular thing.
Also, I believe that showing actually interesting content is bad for the businesses because it might make the user stop to think and pursue something meaningful instead of continuing to use the product.
Spotify is a prime example of this. There are so many “features” I hate and that no one has asked for, yet shuffle doesn’t even work.
Everytime I start spotify in ny office after listening on my commute, it tries to start playing on my phone since that was playing in my car.
Or when I was still there, Reddit search. Absolutely useless and so fucking smarmy with that stupid doge.
What do you mean by “shuffle doesn’t even work”? Please qualify that statement.
they may be referring to how spotify’s shuffle isn’t a true “shuffle” in that it is biased to things you have listened to more, recently, etc
That’s been the case for well over a decade going back to some of the earliest iPods. It’s nothing new.
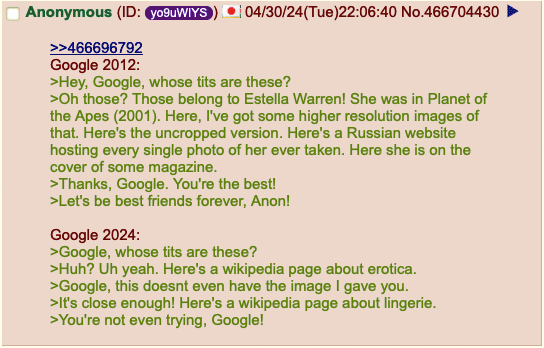
Unrealistic. I usually have to scroll way down in the results to find a link to wikipedia nowadays.
Yandex, my friends
I don’t even care if the results are good. I’m not about to use any part of RUnet.
Honest question: why not? Facebook/Google/Microsoft are up to some disgusting shit, are their Russian counterparts significantly different?
Privacy, for one thing. I don’t use Google, Bing, Windows, or any Meta software*, and Yandex aren’t much different.
Security, though, is another thing. I live in a NATO country, and I would imagine the Russian government are monitoring Yandex (and other RUnet services). Frankly, I think contributing any data to such a government would be against my interests.
There’s also a lot of censorship on RUnet. Yeah, Google has that too, but Mojeek and Brave Search do not.
TL;DR: Google is data-hungry and supplies data to the NSA; Yandex is data-hungry and supplies data to the Kremlin; Mojeek and Brave Search are good; DDG and Startpage are the best for the average user.
Why noy? RuTracker is better than any other tracker, open or private.
I’m going to make the assumption that a lot of people on Lemmy are FOSS enthusiasts and are therefore adverse to anything closed source, especially a Russian web service…
What? We’re talking about websites, not software here
Guess what websites are made of
Oh I know this one!
It’s pipes, right‽
Tubes
Perversity and males in Japan. Name a better team.







{kind=link}